Kestra là một nền tảng điều phối (orchestration) và lập lịch (scheduling) mã nguồn mở tiên tiến, được thiết kế để đơn giản hóa việc quản lý và tự động hóa các quy trình công việc phức tạp. Với mục tiêu mang lại sự linh hoạt, khả năng mở rộng và dễ sử dụng, Kestra cho phép các kỹ sư, nhà phát triển dữ liệu và cả người dùng không chuyên xây dựng, vận hành và giám sát các quy trình công việc từ dữ liệu đến vi dịch vụ một cách hiệu quả. Được xây dựng dựa trên các công nghệ hiện đại như Apache Kafka và Elasticsearch, Kestra đang trở thành một lựa chọn thay thế mạnh mẽ cho các công cụ như Airflow, Zapier hay Rundeck.
Kestra là gì?
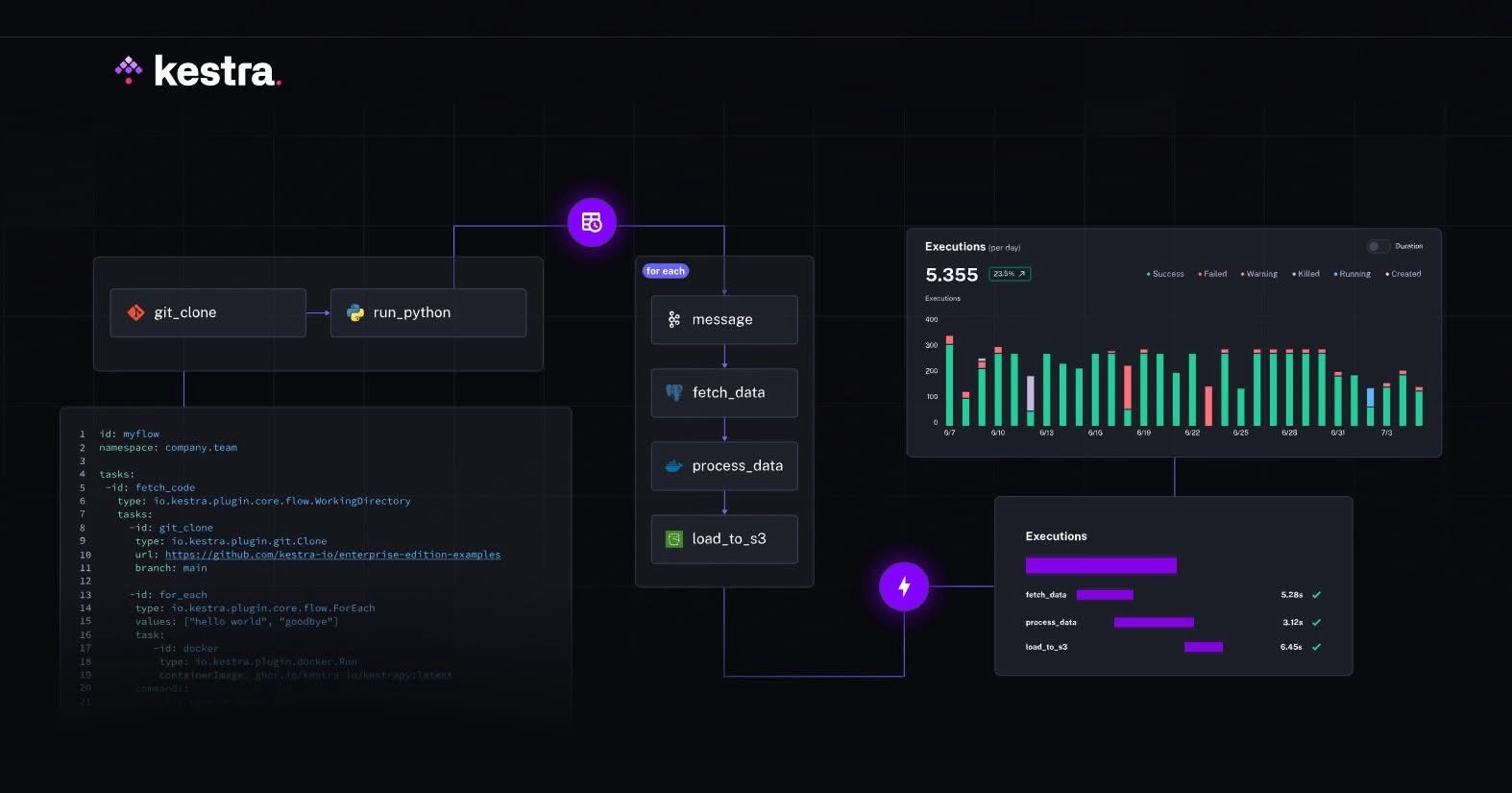
Kestra là một nền tảng điều phối sự kiện (event-driven orchestration platform) cho phép người dùng định nghĩa các quy trình công việc (workflows) thông qua cú pháp YAML đơn giản hoặc giao diện người dùng trực quan. Mỗi quy trình công việc, được gọi là Flow, là tập hợp các nhiệm vụ (tasks) được thực thi theo trình tự hoặc song song, có thể tích hợp với hàng trăm dịch vụ và công cụ thông qua hệ thống plugin phong phú. Kestra hỗ trợ cả các tác vụ theo lịch (scheduled) và theo sự kiện (event-driven), giúp nó phù hợp với nhiều trường hợp sử dụng từ xử lý dữ liệu lớn, ETL/ELT, đến tự động hóa quy trình kinh doanh.
Điểm nổi bật của Kestra là sự kết hợp giữa tính dễ sử dụng cho người mới và tính linh hoạt cho các nhà phát triển dày dạn kinh nghiệm. Bạn có thể bắt đầu với giao diện kéo-thả hoặc viết mã YAML trực tiếp, đồng thời tận dụng các tính năng như tích hợp Git, CI/CD và Terraform để quản lý quy trình công việc như mã nguồn (Everything as Code).
Các tính năng nổi bật của Kestra
1. Định nghĩa quy trình công việc bằng YAML: Sử dụng cú pháp YAML rõ ràng để mô tả các Flow, giúp dễ dàng đọc, chia sẻ và duy trì. Mọi thay đổi trong giao diện người dùng đều được tự động đồng bộ với mã YAML, đảm bảo tính nhất quán.
2. Hệ thống plugin phong phú: Với hơn 600 plugin, Kestra tích hợp dễ dàng với các công cụ như AWS, Google Cloud, Snowflake, dbt, Apache Spark, Kafka, và nhiều cơ sở dữ liệu (MySQL, PostgreSQL, BigQuery, v.v.). Người dùng cũng có thể tạo plugin tùy chỉnh.
3. Giao diện người dùng trực quan: Kestra cung cấp UI thân thiện với trình chỉnh sửa mã tích hợp (hỗ trợ tô sáng cú pháp, tự động hoàn thành), biểu đồ Gantt để theo dõi tiến độ, và khả năng xem log chi tiết để xử lý lỗi nhanh chóng.
4. Hỗ trợ đa ngôn ngữ: Kestra là nền tảng không phụ thuộc ngôn ngữ (language-agnostic), cho phép thực thi các tác vụ viết bằng Python, R, Java, Shell, Node.js, hoặc bất kỳ ngôn ngữ nào khác.
5. Khả năng mở rộng và kiến trúc cloud-native: Được xây dựng trên Kafka và Elasticsearch, Kestra có thể xử lý khối lượng công việc lớn mà không gặp điểm nghẽn (single point of failure). Nó hỗ trợ triển khai trên Kubernetes, Docker, hoặc on-premise.
6. Tích hợp Git và CI/CD: Quy trình công việc được lưu trữ trên Git, cho phép version control, rollback, và tích hợp với các pipeline CI/CD.
7. Tự động hóa theo sự kiện và lịch trình: Kestra hỗ trợ các trigger theo thời gian thực (real-time event triggers) từ Kafka, SQS, hoặc API, cùng với lịch trình cron linh hoạt.
8. Quản lý lỗi và độ tin cậy: Các tính năng như retries, timeout, error handling, và subflows đảm bảo quy trình công việc hoạt động ổn định ngay cả khi xảy ra lỗi.
Lợi ích của Kestra
• Dễ dàng bắt đầu: Người dùng không cần kiến thức lập trình sâu vẫn có thể tạo quy trình công việc thông qua giao diện kéo-thả hoặc các mẫu (blueprint) có sẵn.
• Tiết kiệm thời gian: Tự động hóa các tác vụ phức tạp và giảm thời gian thiết lập nhờ hệ thống plugin và tích hợp sẵn.
• Phù hợp cho nhiều đối tượng: Từ kỹ sư dữ liệu, lập trình viên, đến nhân viên kinh doanh, Kestra phá vỡ rào cản giữa các nhóm nhờ giao diện chung và khả năng cộng tác.
• Khả năng mở rộng vượt trội: Không giới hạn về quy mô, Kestra phù hợp cho cả startup và doanh nghiệp lớn như Tencent, BMW hay Leroy Merlin.
• Miễn phí và mã nguồn mở: Là dự án mã nguồn mở, Kestra cho phép sử dụng miễn phí, triển khai linh hoạt, và nhận được sự hỗ trợ từ cộng đồng đông đảo.
Hạn chế cần lưu ý
• Độ phức tạp ban đầu: Mặc dù giao diện thân thiện, việc làm quen với YAML và các khái niệm như Flow, Namespace có thể mất thời gian với người mới.
• Phụ thuộc vào plugin: Một số tích hợp đặc thù có thể yêu cầu phát triển plugin tùy chỉnh nếu chưa có sẵn.
• Tài liệu cần cải thiện: Dù tài liệu của Kestra khá đầy đủ, một số phần vẫn đang được hoàn thiện, đặc biệt cho các tính năng nâng cao.
Ai nên sử dụng Kestra?
• Kỹ sư dữ liệu: Những người cần xây dựng pipeline ETL/ELT, xử lý dữ liệu lớn, hoặc tích hợp với kho dữ liệu (data warehouse).
• Lập trình viên DevOps: Các đội ngũ muốn tự động hóa cơ sở hạ tầng, quản lý CI/CD, hoặc triển khai ứng dụng.
• Nhóm kinh doanh: Nhân viên không chuyên về kỹ thuật có thể sử dụng giao diện UI để tự động hóa quy trình như gửi email, báo cáo, hoặc quản lý tác vụ.
• Doanh nghiệp lớn và startup: Kestra phù hợp với các tổ chức cần một giải pháp điều phối linh hoạt, từ các dự án nhỏ đến hệ thống quy mô lớn.
So sánh với các công cụ khác
So với Apache Airflow, Kestra có ưu điểm về giao diện thân thiện hơn, cú pháp YAML dễ đọc, và khả năng xử lý sự kiện theo thời gian thực. Airflow mạnh hơn về cộng đồng và các tính năng dành cho lập trình viên Python, nhưng có thể phức tạp hơn khi mở rộng. So với Prefect hay Dagster, Kestra nổi bật nhờ tính không phụ thuộc ngôn ngữ và khả năng tích hợp đa dạng, trong khi các công cụ kia tập trung nhiều vào Python.
Kết luận
Kestra là một nền tảng điều phối mạnh mẽ, dễ sử dụng và linh hoạt, mang đến cách tiếp cận hiện đại cho việc tự động hóa quy trình công việc. Với kiến trúc mở rộng, hệ thống plugin đa dạng và triết lý “Everything as Code”, Kestra không chỉ giúp các đội ngũ kỹ thuật tiết kiệm thời gian mà còn tạo điều kiện để mọi người trong tổ chức tham gia vào quá trình tự động hóa. Nếu bạn đang tìm kiếm một giải pháp thay thế cho Airflow hoặc muốn đơn giản hóa các pipeline dữ liệu, Kestra chắc chắn là công cụ đáng để thử.
Hãy truy cập kestra.io để trải nghiệm và bắt đầu xây dựng quy trình công việc của riêng bạn